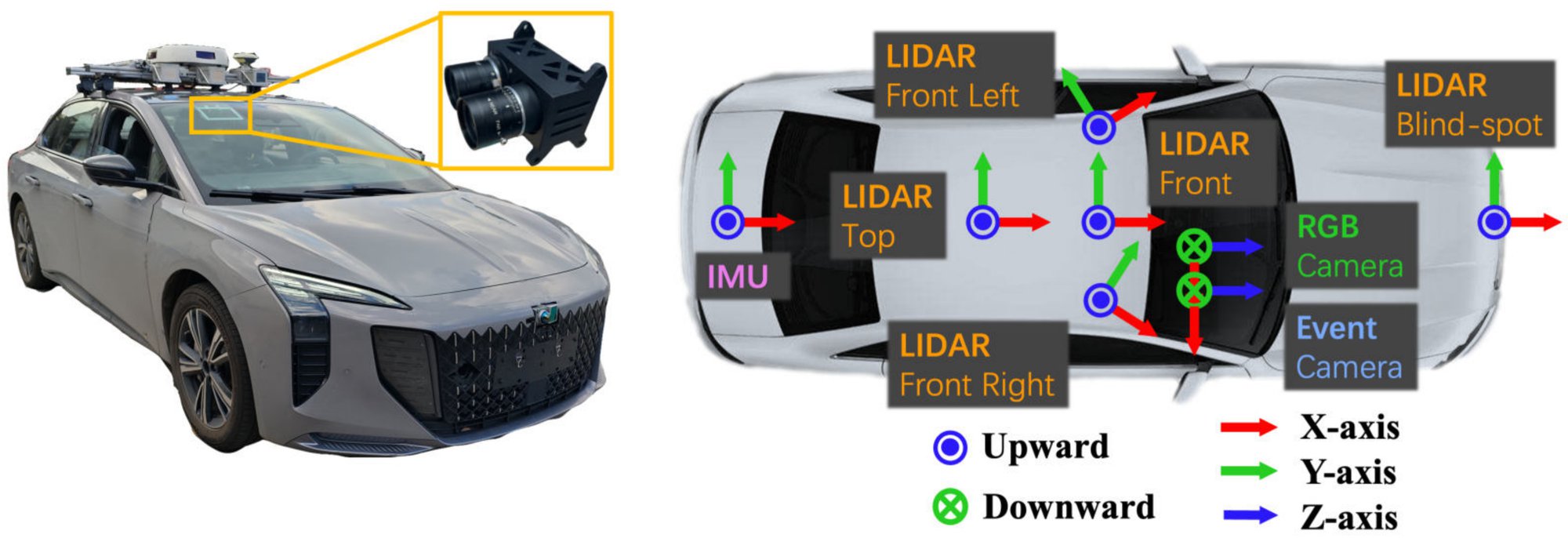
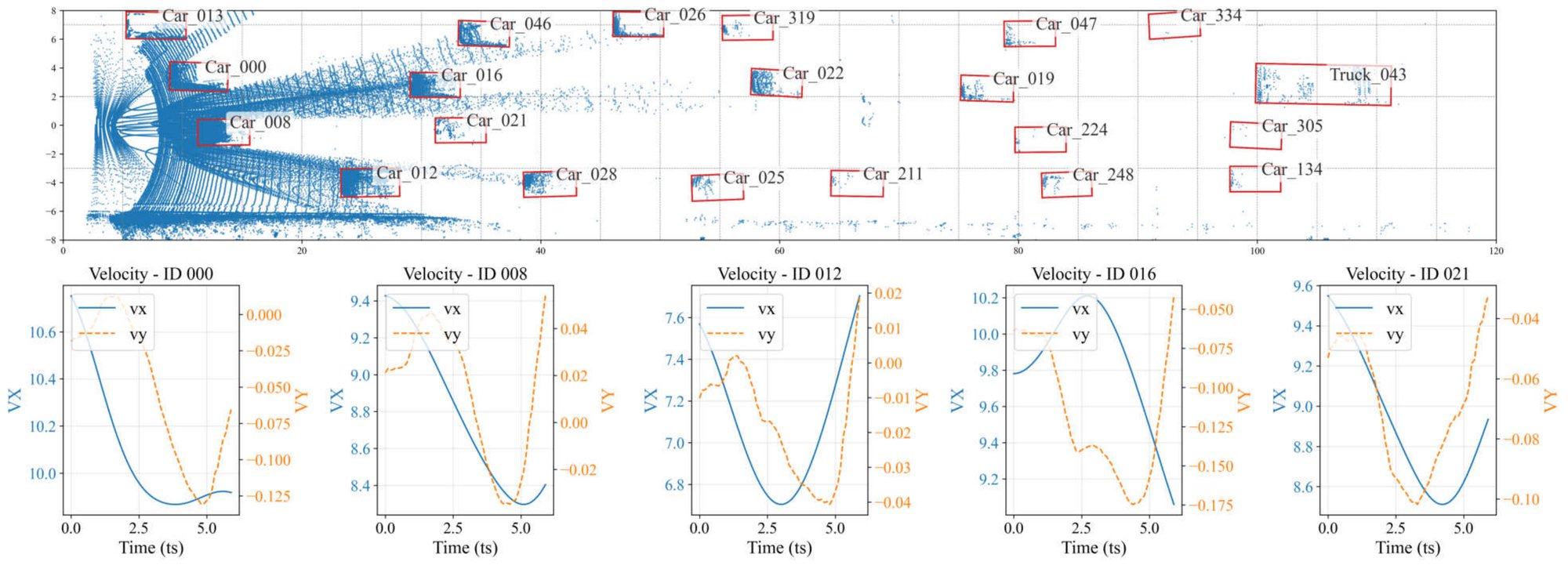
IEEE Transactions on Robotics (T-RO) 2026
Toward Deep Representation Learning for Event-enhanced Visual Autonomous Perception:
the eAP Dataset
Jinghang Li*,1, Shichao Li*,2, Qing Lian2, Peiliang Li2, Xiaozhi Chen2, Yi Zhou†,1
1 Neuromorphic Automation and Intelligence Lab (NAIL), Hunan University
2 Zhuoyu Technology
* Equal contribution † Corresponding author: Yi Zhou